

In today's data-driven world, scaling your data pipelines is crucial for the success of your data engineering projects. Whether you are dealing with large amounts of data or experiencing an increasing demand for real-time data processing, scaling your pipelines is essential to ensure optimal performance and efficiency. In this guide, we will explore the importance of scaling, different scaling methods, and how to choose the right scaling strategy for your business.
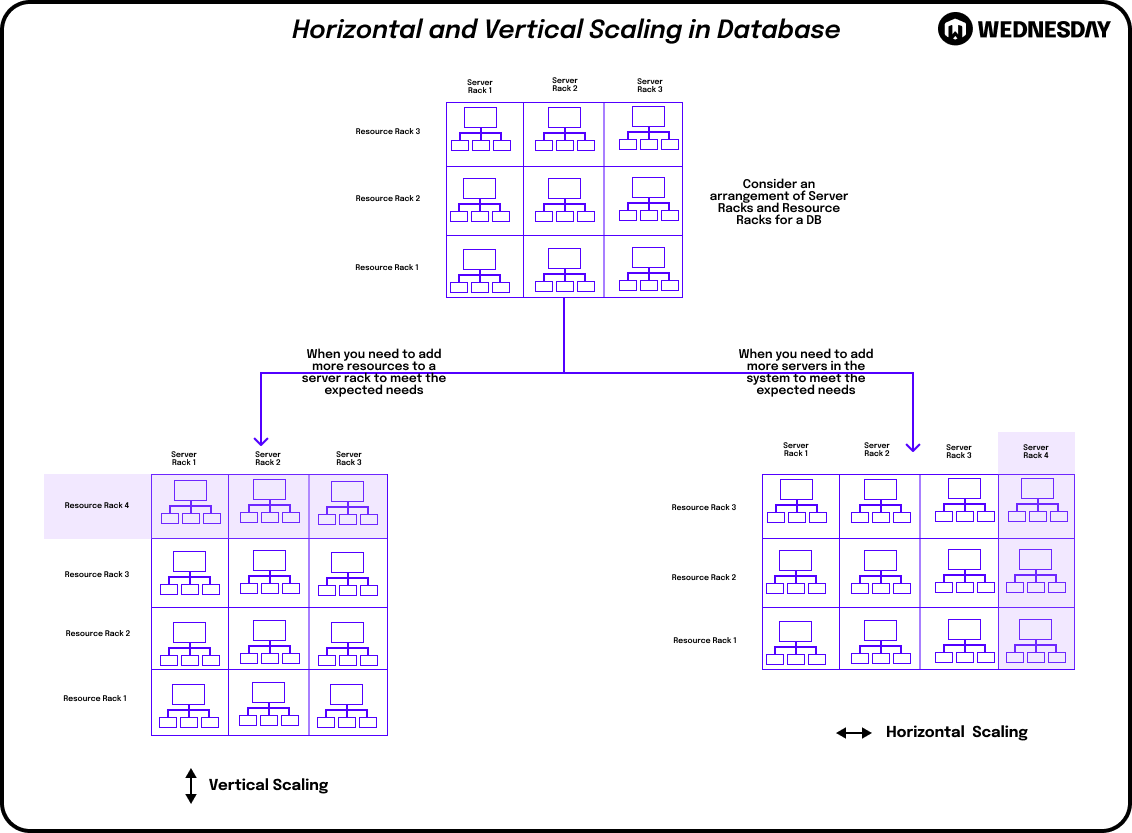
Getting Started: An Introduction to Scaling
Scaling refers to the process of increasing the capacity and capabilities of your data pipelines to handle growing workloads. As your business expands and data volumes grow, scaling becomes necessary to maintain the speed and reliability of your data processing. By scaling your pipelines, you can ensure that your system can handle the increased load and meet the growing demands of your data-driven applications.
Understanding the Importance of Scaling
Scaling is vital for several reasons. First and foremost, it allows you to keep up with the ever-increasing amounts of data generated by modern businesses. As the volume, velocity, and variety of data continue to grow, scaling your pipelines ensures that you can process this data in a timely manner.
Furthermore, scaling improves the reliability and availability of your data pipelines. By distributing the workload across multiple resources, you can reduce the risk of bottlenecks and single points of failure. This redundancy helps ensure uninterrupted data processing, minimizing downtime and improving the overall resilience of your system.
Another important aspect of scaling is its impact on cost efficiency. By scaling your pipelines, you can optimize resource utilization and avoid overprovisioning. This means that you only allocate resources as needed, reducing unnecessary expenses and maximizing the return on your investment.
Moreover, scaling enables you to adapt to changing business requirements and market conditions. As your business grows, you may need to process data from new sources or handle increased data complexity. Scaling your pipelines allows you to accommodate these changes without disrupting your existing data processing workflows.
The Need for Scaling: Why It Matters

Scaling your data pipelines offers various benefits that directly impact your business's performance and bottom line. Let's take a closer look at why scaling matters and how it can drive your organization forward.
Exploring the Benefits of Scaling
1. Increased Throughput: Scaling allows your pipelines to process a higher volume of data, resulting in improved productivity and faster insights. By distributing the workload across multiple resources, you can handle larger datasets and deliver results more efficiently.
2. Better Performance: Scaling your pipelines helps maintain optimal performance even during peak times. By adding more resources, you can handle sudden spikes in demand without compromising speed or accuracy. This ensures that your applications and services remain responsive and deliver a great user experience.
3. Cost Optimization: While scaling does require additional resources, it can also help optimize costs in the long run. By efficiently allocating resources and dynamically adjusting capacity based on demand, you can avoid overprovisioning and reduce operational expenses.
Now, let's delve deeper into each of these benefits to gain a comprehensive understanding of how scaling can truly transform your data pipelines and propel your organization toward success.
Increased Throughput: When it comes to data processing, speed is of the essence. By scaling your pipelines, you can significantly increase the throughput, allowing you to process a higher volume of data in a shorter amount of time. This means that you can generate insights and make data-driven decisions more quickly.
Better Performance: In today's digital landscape, user experience is paramount. By scaling your pipelines, you can ensure that your applications and services consistently deliver optimal performance, even during peak usage periods. This means that your customers can access your services without any slowdowns or disruptions, resulting in higher satisfaction and increased loyalty.
Cost Optimization: While scaling may seem like an additional expense, it can actually help optimize costs in the long run. By dynamically adjusting the capacity of your pipelines based on demand, you can avoid overprovisioning and wasting resources. This allows you to allocate your resources efficiently, reducing operational expenses and maximizing the return on your investment.
By understanding the intricacies of scaling and its benefits, you can make informed decisions and implement strategies that will drive your organization forward. Whether you are a small startup or a large enterprise, scaling your data pipelines is essential for staying competitive in today's data-driven world.
Exploring Different Scaling Methods
When it comes to scaling your data pipelines, there are different approaches you can take. Understanding the advantages and considerations of each method will help you choose the right scaling strategy for your specific requirements.
Scaling Up vs. Scaling Out: Which Approach is Right for You?
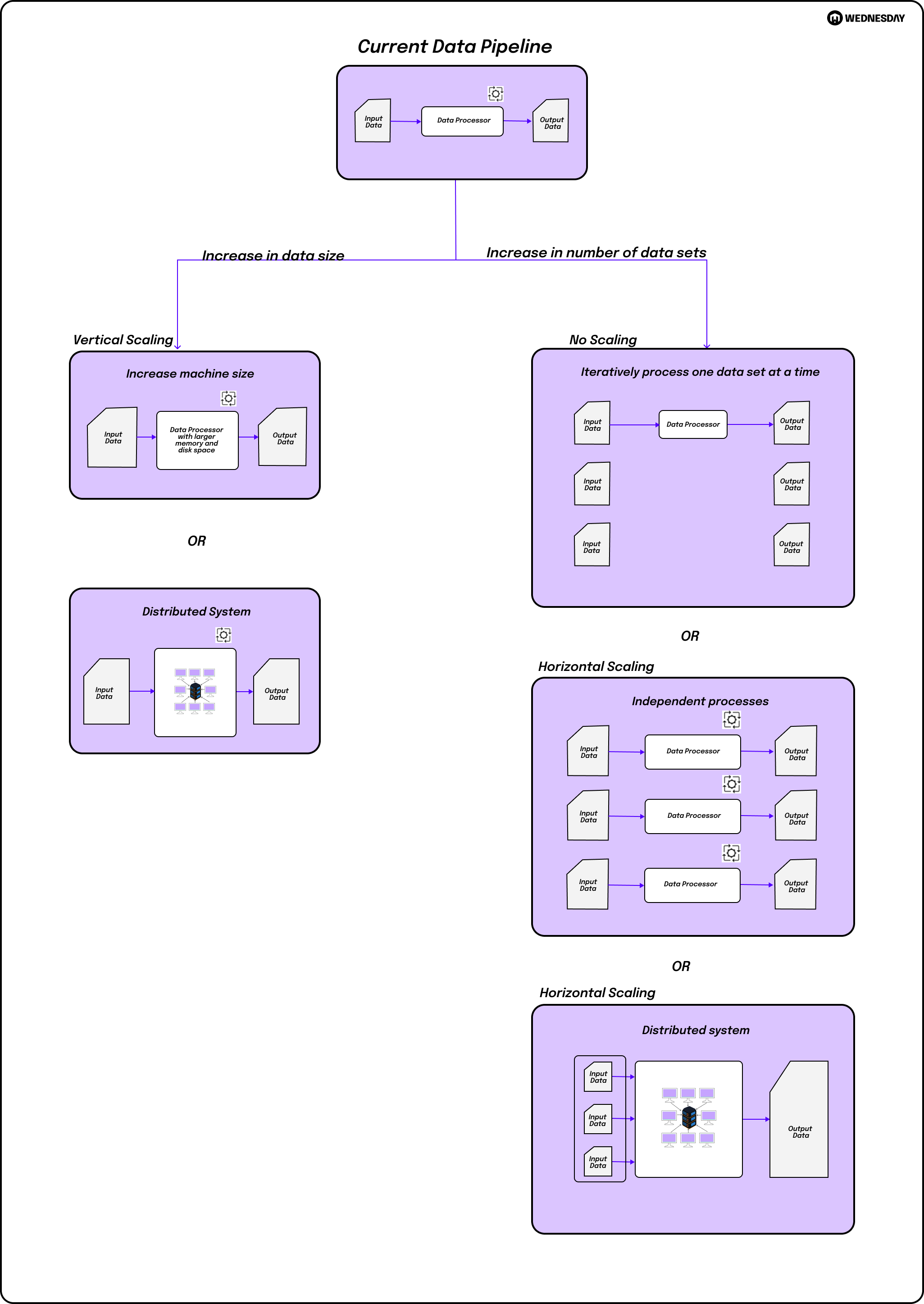
Scaling up, also known as vertical scaling, involves increasing the capacity of your existing infrastructure resources. This can be achieved by adding more memory, storage, or processing power to your servers. Scaling up is suitable when your pipeline's performance can be improved by enhancing the capabilities of a single resource.
On the other hand, scaling out, or horizontal scaling, involves adding more instances or nodes to your infrastructure. Each instance runs parallel to handle a portion of the workload. Scaling out is ideal for distributed systems and allows you to handle larger workloads by dividing them across multiple resources.
The Pros and Cons of Vertical Scaling

Vertical scaling offers several advantages, such as:
- Easy to implement and requires minimal changes to your existing infrastructure.
- Allows you to make the most of your current resources by improving their capabilities.
- Can result in better performance for workloads that primarily rely on a single resource.
However, vertical scaling also has its limitations:
- There is a finite limit to how much you can vertically scale a resource, which can restrict long-term scalability.
- Costs can escalate rapidly as you need to invest in high-end hardware or licenses for more powerful resources.
- Vertical scaling does not provide the same level of fault tolerance and redundancy as horizontal scaling.
The Pros and Cons of Horizontal Scaling
Horizontal scaling offers several advantages, such as:
- Provides high availability and fault tolerance by distributing the workload across multiple resources.
- Offers virtually unlimited scalability by adding more instances to handle increasing workloads.
- Can be more cost-effective in the long run as you can start with lower-cost resources and scale as needed.
However, horizontal scaling also has its limitations:
- Requires additional considerations for managing data consistency across distributed resources.
- May introduce more complexity in terms of configuration and coordination between different instances.
- Not all applications or workloads are suitable for horizontal scaling, especially those that heavily rely on single-threaded or sequential processing.
Now that we have explored the pros and cons of vertical and horizontal scaling, it's important to consider the impact of these scaling methods on your overall system architecture. Vertical scaling, with its focus on enhancing the capabilities of a single resource, can be a straightforward solution for improving performance. However, as your workload grows, you may reach the limits of vertical scaling, and the costs associated with upgrading hardware or licenses may become prohibitive.
Horizontal scaling, on the other hand, offers a more flexible and scalable approach. By distributing the workload across multiple resources, you can achieve high availability and fault tolerance. This can be particularly beneficial for applications that require continuous uptime and can handle the complexity of managing data consistency across distributed resources. Additionally, horizontal scaling allows you to start with lower-cost resources and scale as needed, providing a more cost-effective solution in the long run.
Here is a comparison of the different scaling strategies:
Choosing the Right Scaling Strategy for Your Business
When it comes to selecting a scaling approach for your business, there are several factors that you need to carefully consider. These factors will help ensure that you choose the best fit for your specific requirements and objectives, allowing you to effectively manage your business growth.
Factors to Consider When Selecting a Scaling Approach
1. Workload Characteristics: One of the first things you need to evaluate is the nature of your workload. Consider factors such as data volume, processing requirements, and peak times. By understanding these characteristics, you can determine whether vertical or horizontal scaling aligns better with your workload. Vertical scaling involves adding more resources to a single server, while horizontal scaling involves adding more servers to distribute the workload.
2. Scalability Requirements: It's important to consider the scalability needs of your data engineering projects. Ask yourself whether short-term scalability bursts are sufficient for your business or if you require long-term scalability to accommodate future growth. This will help you determine the scalability approach that best suits your needs.
3. Cost-Effectiveness: Balancing costs is always a crucial aspect of any business decision. When it comes to scaling, it's important to compare the upfront expenses of vertical scaling with the long-term benefits and cost savings offered by horizontal scaling. Consider factors such as hardware costs, maintenance expenses, and the potential for future scalability.
4. System Complexity: Assessing the complexity of your system is essential in determining the appropriate scaling strategy. Take into account your infrastructure and applications, and evaluate whether they are ready to support horizontal scaling or if vertical scaling provides a simpler solution. Consider factors such as system architecture, software compatibility, and the expertise required to implement and manage the chosen scaling approach.
5. Data Consistency: Maintaining data consistency is a critical consideration when choosing a scaling strategy. Analyze the need for consistent data across distributed resources and identify any potential challenges or requirements that might impact your choice. This could include factors such as data replication, synchronization mechanisms, and the impact on overall system performance.
By carefully considering these factors, you can make an informed decision when selecting the right scaling strategy for your business. Remember, scalability is not a one-size-fits-all solution, and what works for one business may not work for another. Take the time to evaluate your specific needs and objectives, and choose a scaling approach that will support your business growth effectively.
Wrapping Up: Key Takeaways on Scaling
In conclusion, scaling your data pipelines is an essential aspect of data engineering. It enables you to handle increasing workloads, improve performance, and optimize costs. By understanding the importance of scaling, exploring different scaling methods, and considering your business's specific needs, you can choose the right scaling strategy that aligns with your goals and accelerates your data-driven success.
Scaling is not a one-time event but an ongoing process. Regularly evaluate and monitor your data pipelines to ensure they continue to meet your changing requirements. With the right scaling strategy in place, you can confidently navigate the ever-expanding world of data engineering and unlock the full potential of your data pipelines.
As you look to scale your data pipelines and embrace the challenges of data engineering, remember that you don't have to do it alone. If you’d like to learn about our services and how we can help you please book a free consult here.
