


In today's data-driven world, having a robust and efficient data environment is crucial for organizations of all sizes. The process of setting up and maintaining a data environment can be complex and time-consuming, but with the advent of open table formats, it has become much simpler and more flexible. In this article, we explore the various benefits of using an open table format for setting up your data environment.
Setting Up Your Data Environment
Before we delve into the benefits of using an open table format, let's first understand what it entails to set up a data environment. When setting up your data environment, you need to consider various factors such as data storage, data processing, and data access. Traditionally, this involved creating and managing multiple data silos, each with its own storage and processing mechanisms.
However, with the open table format, you can consolidate all your data into a single, unified format. This format allows for seamless integration and interoperability across different systems and tools, making it much easier to manage your data environment efficiently.
But what exactly does it mean to set up a data environment? Let's explore this further.
Setting up a data environment involves carefully planning and implementing the infrastructure required to store, process, and access your data. It's like building the foundation for a house - without a solid foundation, the entire structure can collapse.
Now that we understand the benefits of using an open table format, let's dive into the step-by-step process of setting up your data infrastructure.
A Step-by-Step Guide to Setting Up Your Data Infrastructure
Step 1: Define your data requirements: Understand the type of data you'll be working with and the specific needs of your organization. This includes identifying the sources of your data and determining the volume, velocity, and variety of the data.
Step 2: Choose the right open table format: There are several open table formats available, such as Apache Parquet and Apache Avro. Consider the features and compatibility of each format to choose the one that best fits your requirements. Take into account factors like data compression, columnar storage, and schema evolution capabilities.
Step 3: Design your data schema: Plan out the structure of your data tables, including the fields, data types, and relationships between tables. This step is crucial as it determines how your data will be organized and accessed.
Step 4: Create your data tables: Implement your data schema and create the necessary tables in your chosen open table format. This involves defining the columns, data types, and constraints for each table.
Step 5: Load your data: Populate your tables with the relevant data from your sources, such as databases, CSV files, or streaming platforms. This can be done using various data loading techniques, including batch loading and real-time streaming.
Step 6: Optimize for performance: Fine-tune your data environment for optimal performance by implementing techniques such as data partitioning and indexing. This ensures that your queries run efficiently and your data processing tasks are executed in a timely manner.
Step 7: Test and validate: Thoroughly test your data environment to ensure that it functions as expected and meets your organization's requirements. This includes validating the data integrity, performing performance testing, and verifying the accuracy of the results.
Evolving Data and Partition Schema: A Seamless Process
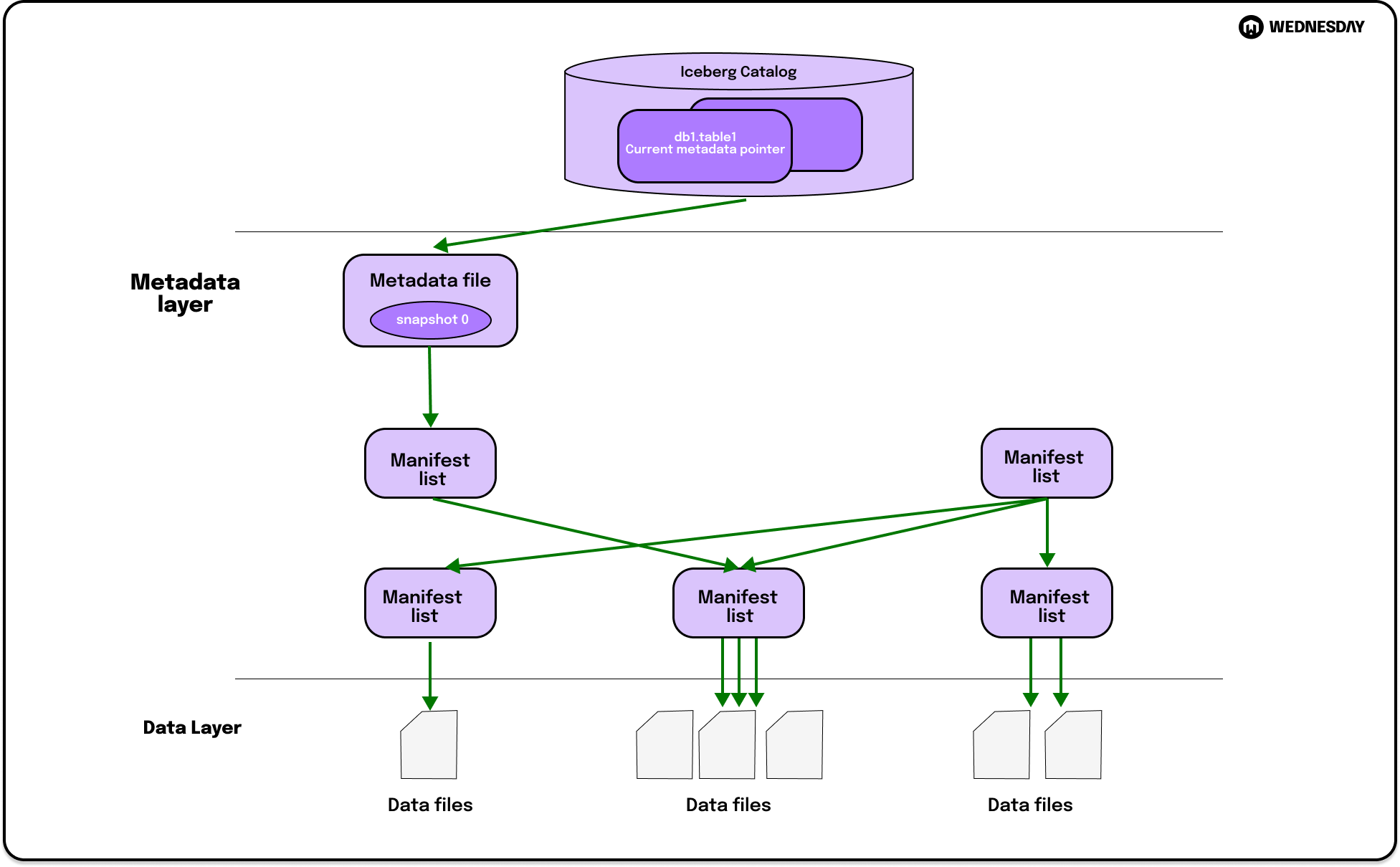
One of the biggest challenges in managing a data environment is dealing with evolving data and partition schema. As your organization grows and your data volumes increase, you may need to modify your data schema or partitioning strategy to accommodate changing requirements.
Traditionally, making changes to data schema or partitioning would require extensive reprocessing and migration efforts, resulting in significant downtime and disruption. However, with an open table format, this process becomes much more seamless and efficient.
With an open table format, you can modify your data schema or partitioning strategy without having to reprocess your entire dataset. This is achieved through the use of columnar storage and metadata management, which allows for efficient data updates and schema evolution.
By adopting an open table format, you can easily adapt to changing business needs without incurring significant downtime or disruption to your data environment.
How to Modify Data and Partition Schema Without the Need for Reprocessing
Modifying your data and partition schema without the need for reprocessing is a powerful capability offered by an open table format. Here are some strategies to achieve this:
- Column-level updates: With an open table format, you can update specific columns within a table without having to rewrite the entire dataset. This allows for more efficient data updates and reduces the time and resources required for schema modifications.
- Metadata management: By separating the metadata from the actual data, you can easily modify the structure and organization of your data without impacting the underlying data. This allows for seamless schema evolution and simplifies the process of partition management.
- Incremental processing: Rather than reprocessing the entire dataset, an open table format enables you to process only the incremental changes. This significantly reduces processing time and resources while ensuring that your data remains up-to-date.
By leveraging these strategies, you can modify your data and partition schema in a seamless and efficient manner, without the need for extensive reprocessing.
Time Travel: Exploring Previous Table States

Another valuable feature of an open table format is the ability to explore previous table states, also known as time travel. Time travel allows you to query your data as it existed at a specific point in time, enabling you to conduct retrospective analysis and gain insights into historical trends and patterns.
With traditional data storage formats, such as relational databases, accessing historical data can be a laborious and time-consuming process. Historical data is often stored in separate tables or backups, requiring complex joins or restores to retrieve the desired information.
However, with an open table format, historical data is seamlessly integrated into your data environment, allowing for easy exploration and analysis. You can query your data as it existed at different points in time without the need for complex joins or restores.
This capability not only simplifies the process of accessing historical data but also enhances your ability to gain insights from past events and make informed decisions based on historical trends.
Unlocking the Power of Time Travel in Your Data Analysis
Time travel in your data analysis can be a powerful tool for understanding the evolution of your data and identifying patterns and trends over time. Here are a few ways to unlock the power of time travel:
- Identify trends: By analyzing data at different points in time, you can identify trends and patterns that may not be apparent when analyzing current data alone. This can help you make data-driven decisions and anticipate future trends.
- Perform root cause analysis: Time travel allows you to trace back the changes in your data and identify the root causes of issues or anomalies. This can help you rectify problems more effectively and prevent similar issues in the future.
- Compliance and auditing: Time travel provides a reliable audit trail of changes made to your data, making it easier to meet compliance requirements and perform thorough audits.
By utilizing time travel in your data analysis, you can unlock new insights and gain a deeper understanding of your data, ultimately leading to better decision-making and improved business outcomes.
Branches and Tags for Your Tables: A Git-Like Approach

Version control is a crucial aspect of managing data environments, as it allows you to track changes, collaborate effectively, and roll back to previous states if needed. An open table format enables you to leverage a Git-like approach to version control using branches and tags.
With branches and tags, you can create different versions of your tables, each representing a different point in time or a specific set of changes. This allows for parallel development and experimentation without affecting the integrity of your production data.
Branches enable you to work on new features or modifications in isolation without impacting the main data environment. Tags, on the other hand, allow you to mark specific versions of your tables, making it easy to roll back to a known state if necessary.
This Git-like approach to version control simplifies collaboration, enhances reproducibility, and provides a level of flexibility and control not possible with traditional data storage formats.
Managing Table Versions with Branches and Tags
Managing table versions with branches and tags follows a similar workflow to Git, making it familiar to developers and data engineers. Here's a high-level overview of the process:
- Create a branch: Start by creating a new branch from your main data table. This branch represents a separate line of development.
- Make changes: Make the necessary modifications or additions to the data within the branch. These changes are isolated from the main data table.
- Merge or revert: Once the changes in the branch are tested and validated, you can merge them back into the main data table or revert to a previous state using tags.
Concurrent Reads and Writes: Ensuring Smooth Data Operations
In a data-centric environment, it is common for multiple users or processes to simultaneously read from and write to the data tables. Ensuring smooth and efficient data operations in such scenarios can be challenging, especially in traditional data storage formats.
However, with an open table format, concurrent reads and writes can be effectively managed, minimizing conflicts and maximizing performance. This is achieved through various strategies and optimizations tailored for open table formats.
Here are some strategies for handling multiple simultaneous reads and writes:
Strategies for Handling Multiple Simultaneous Reads and Writes
- Parallelism: Open table formats are designed to take advantage of parallel processing capabilities, allowing for concurrent reads and writes across multiple threads or nodes. This improves overall performance and throughput.
- Optimistic concurrency control: By implementing optimistic concurrency control mechanisms, conflicts between simultaneous writes can be detected and resolved without blocking other operations. This ensures smooth and uninterrupted data operations.
- Data isolation: Open table formats provide mechanisms for isolating data at various levels, such as table-level or row-level isolation. This prevents unwanted interference between concurrent operations and maintains data integrity.
- Transaction management: Open table formats often support transactional operations, ensuring that sequences of reads and writes are atomic and consistent. This guarantees data integrity and concurrency control.
By implementing these strategies, you can ensure smooth data operations in your open table environment, even when dealing with multiple simultaneous reads and writes.
Where to go from here?
Using an open table format for setting up your data environment offers numerous benefits. From simplifying the process of setting up your data infrastructure to enabling seamless modification of data and partition schema, open table formats provide a flexible and efficient solution. Additionally, the ability to explore previous table states through time travel, adopt a Git-like approach to version control, and handle concurrent reads and writes efficiently are invaluable features that enhance the overall usability and effectiveness of your data environment. Embracing open table formats allows organizations to unleash the true potential of their data and gain a competitive edge in today's data-driven landscape.
If you’d like to learn about our services and how we can help you in your data journey schedule a free consult here.
Enjoyed the article? Join the ranks of elite C Execs who are already benefiting from LeadReads. Joins here.
