
In the third installment of our comprehensive guide on data architecture patterns and data modeling, we will dive into the fascinating world of data architecture. This article will explore various aspects of data architecture, including the staging area, data cleansing, data marts, and different data architecture patterns. We will also discuss specialized data architecture patterns, tools, frameworks, and the power of data modeling.
Note: If you haven’t read Part 1 & Part 2 in this series please do give it a read.
Fundamental Data Architecture of a Data Warehouse
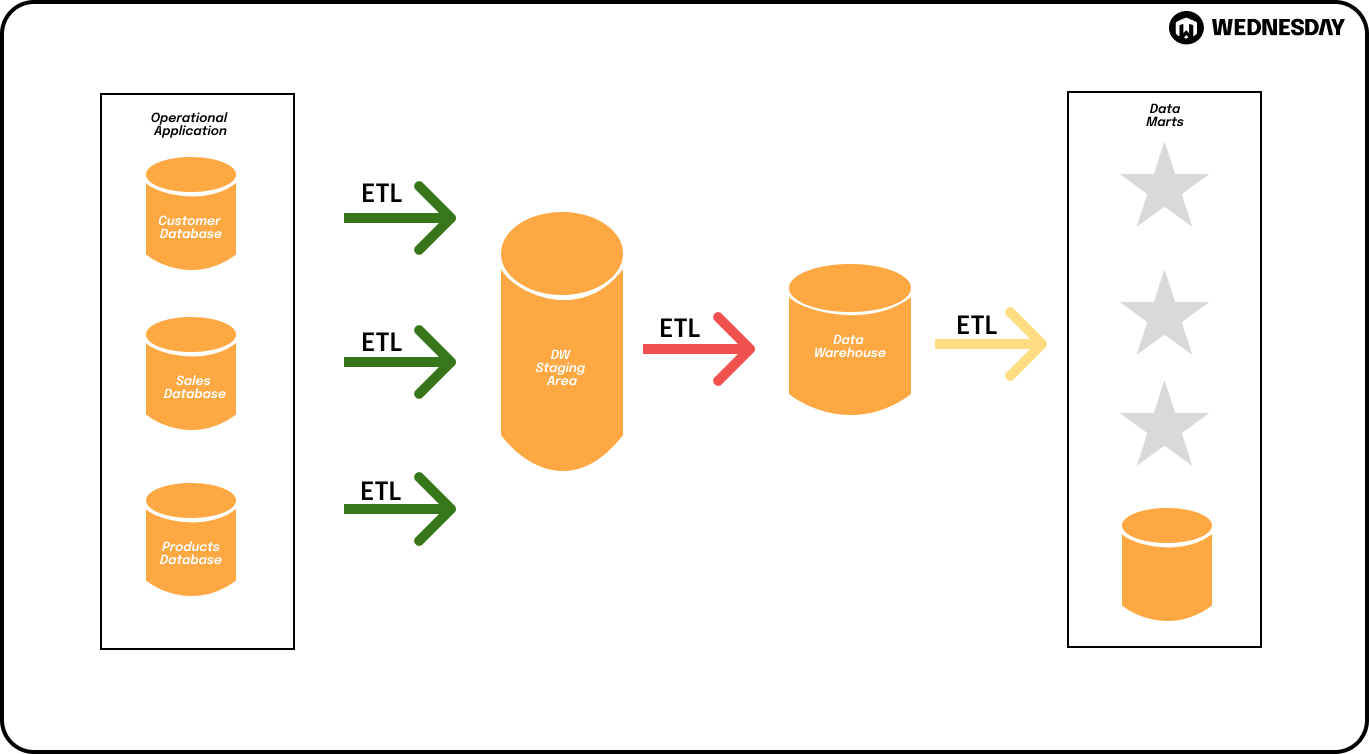
Understanding the Staging Area in Data Architecture
Data architecture involves the collection, storage, organization, and utilization of data. At the heart of data architecture lies the staging area, which serves as a temporary storage location for incoming data. The staging area acts as a buffer, allowing for data transformation, validation, and enrichment before being loaded into the target database or data warehouse.
When data is received from various sources, it may come in different formats, structures, and levels of quality. The staging area provides a controlled environment where data can be standardized, cleaned, and prepared for further processing. This ensures that the data loaded into the target database or data warehouse is consistent and reliable.
Furthermore, the staging area enables organizations to perform complex data transformations and enrichments. This includes tasks such as data deduplication, data validation, data enrichment through external sources, and data aggregation. By leveraging the staging area, organizations can ensure data quality, consistency, and integrity, as well as streamline the data integration process.
The Importance of Data Cleansing in Data Architecture
Data cleansing, also known as data scrubbing, is a critical step in data architecture. It involves identifying and rectifying errors, inconsistencies, and inaccuracies in the data. By cleansing the data, organizations can improve data quality, enhance decision-making, and enable more accurate analysis.
Data cleansing techniques can range from simple rule-based validations to more advanced anomaly detection algorithms. These techniques help identify and correct data errors, such as missing values, incorrect formats, and outliers. Additionally, duplicate record detection algorithms can identify and remove duplicate entries, ensuring data integrity.
Automated data cleansing techniques, such as data validation rules, anomaly detection algorithms, and duplicate record detection, help ensure that the data meets the desired quality standards. This ensures that the data used for analysis and decision-making is accurate, reliable, and free from errors that could lead to incorrect insights or decisions.
Unveiling the Core of Data Architecture
The core of data architecture is the data repository, where structured and unstructured data is stored and organized in a coherent manner. This data repository forms the foundation for data analysis, reporting, and decision-making within an organization.
The data repository is designed to efficiently store and retrieve data, providing fast and reliable access to the information stored within. It includes components such as databases, data warehouses, and data lakes, which are optimized for different types of data and analytical requirements.
Ensuring an efficient and scalable data repository is crucial for leveraging the full potential of data architecture and extracting actionable insights from the vast amount of data available. This involves designing and implementing appropriate data storage and retrieval mechanisms, as well as ensuring data security, privacy, and compliance with regulatory requirements.
Data Marts: Unlocking Insights from Data Architecture
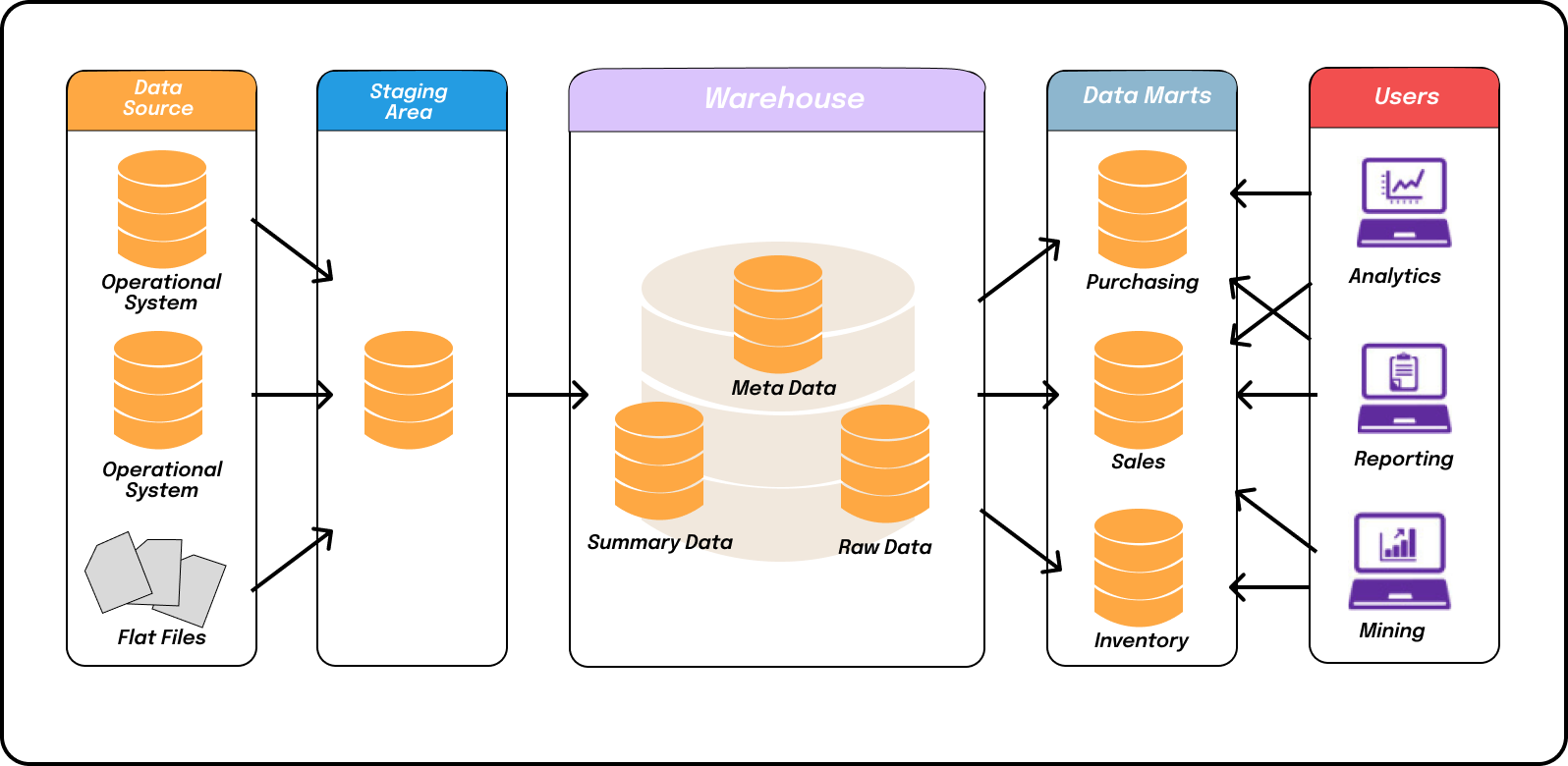
Data marts are subsets of data warehouses that are focused on specific business areas or departments. These specialized databases contain aggregated and summarized data, tailored to meet the specific analytical needs of different user groups.
Data marts are designed to provide quick and easy access to relevant data for specific business functions, such as sales, marketing, finance, or human resources. By consolidating and organizing data in a way that is meaningful to each user group, data marts enable more efficient and effective decision-making and analysis.
By implementing data marts, organizations can achieve better performance, enhanced data accessibility, and faster query response times. This allows business users to retrieve the information they need in a timely manner, without having to navigate through complex and large-scale data warehouses.
The Unique Aspects of Different Data Architecture Patterns
Data architecture patterns can vary significantly based on the organization's requirements, industry, and data complexity. Common data architecture patterns include the hub-and-spoke model, the lambda architecture, and the microservices architecture.
The hub-and-spoke model is characterized by a central data repository (the hub) that serves as a single source of truth, while the spoke systems connect to the hub to exchange data. This pattern provides a centralized approach to data management, ensuring data consistency and integrity across the organization.
The lambda architecture combines batch processing and real-time processing to handle both historical and incoming data. It involves parallel processing of data through two separate layers: the batch layer and the speed layer. This pattern enables organizations to handle large volumes of data and provide real-time insights.
The microservices architecture breaks down data systems into smaller, independent services that can be developed, deployed, and scaled independently. This pattern allows for greater flexibility, agility, and scalability in managing data systems, making it suitable for organizations with rapidly changing data requirements.
Understanding the unique aspects of different data architecture patterns is crucial for choosing the most suitable approach for managing and leveraging data within an organization. It involves considering factors such as data volume, velocity, variety, and the specific business needs and goals of the organization.
The Relevance of Data Architecture Patterns in Today's World
In today's data-driven world, organizations across industries are grappling with the challenge of managing and making sense of ever-increasing volumes of data. Data architecture patterns provide a framework to tackle this challenge by offering scalable, flexible, and efficient solutions.
With the advent of technologies such as big data, cloud computing, and artificial intelligence, the volume and variety of data have grown exponentially. Data architecture patterns help organizations structure and organize this data in a way that enables efficient data processing, analysis, and decision-making.
By adopting and implementing the right data architecture patterns, organizations can unlock the true potential of their data, drive innovation, and gain a competitive edge in the market. Whether it's leveraging real-time insights, optimizing business processes, or improving customer experiences, data architecture patterns play a crucial role in enabling organizations to harness the power of data for strategic advantage.
Enjoying the article? Join the ranks of elite C Execs who are already benefiting from LeadReads. Joins here.
Navigating Specialized Data Architecture Patterns
When it comes to data processing, organizations have two primary options: batch processing and streaming processing. Batch processing involves processing data in large volumes at regular intervals, while streaming processing enables real-time analysis and decision-making based on continuously flowing data.
Choosing the right data processing approach depends on factors such as data velocity, latency requirements, and the specific use cases of the organization.
Batch processing is commonly used when dealing with large volumes of data that can be processed in batches. This approach allows organizations to efficiently process and analyze data in chunks, making it suitable for scenarios where real-time analysis is not a critical requirement. Batch processing can be scheduled to run at specific intervals, such as daily or weekly, allowing organizations to plan and allocate resources accordingly.
On the other hand, streaming processing enables organizations to analyze data in real-time as it flows into the system. This approach is ideal for scenarios where immediate insights and decision-making are crucial, such as fraud detection or real-time monitoring. Streaming processing systems are designed to handle high data velocity and provide low-latency processing, ensuring that organizations can react to events as they happen.
Data lakes and data warehouses are two distinct patterns for storing and managing data. A data lake is a scalable and cost-effective storage repository that stores raw, unprocessed data, while a data warehouse is a structured, organized storage system optimized for query performance and business intelligence.
Deciding between a data lake and a data warehouse depends on factors such as data variety, volume, velocity, and the analytical needs of the organization.
A data lake is designed to store data in its raw form, without any predefined structure or schema. This makes it highly flexible and capable of handling diverse data types, such as structured, semi-structured, and unstructured data. Data lakes are often used for exploratory analysis, data discovery, and data science experiments, as they provide a centralized repository for storing and accessing large volumes of data.
On the other hand, a data warehouse is optimized for query performance and business intelligence. It follows a predefined schema and organizes data into tables and columns, making it easier to query and analyze. Data warehouses are typically used for reporting, ad-hoc queries, and generating insights for decision-making. They provide a structured and controlled environment for data analysis, ensuring data consistency and accuracy.
The semantic layer plays a crucial role in data architecture, providing a unified view and interpretation of data across various sources and systems. It acts as a translation layer, allowing users to access and analyze data without needing to understand the complexities of underlying data structures.
By leveraging the semantic layer, organizations can enable self-service analytics, enhance data governance, and promote data democratization. The semantic layer abstracts the underlying data sources and provides a common language for querying and analyzing data. It enables users to define business terms, hierarchies, and relationships, making it easier to navigate and understand the data.
Modernizing your data stack with open data patterns can bring numerous benefits to organizations. Open data patterns are gaining traction in the data architecture landscape as they enable organizations to leverage open-source tools and technologies to build scalable and cost-effective data architectures. By embracing open data patterns, organizations can reduce vendor lock-in, foster innovation, and benefit from the collective knowledge of the open-source community.
Adopting open data patterns requires careful evaluation of the organization's needs, technical capabilities, and long-term goals. It involves selecting the right open-source tools and technologies, establishing best practices, and ensuring proper integration with existing systems and processes. Open data patterns can provide organizations with the flexibility and agility needed to adapt to changing business requirements and technological advancements.
Understanding imperative and declarative data architecture patterns is essential for effective data management and processing. Imperative patterns involve specifying detailed instructions on how to process the data, while declarative patterns focus on defining the desired outcome and leaving the implementation details to the underlying systems.
Choosing between imperative and declarative patterns depends on factors such as data complexity, system interoperability, and resource constraints. Imperative patterns provide fine-grained control over the data processing logic, allowing organizations to optimize performance and customize the processing steps. Declarative patterns, on the other hand, abstract the implementation details and provide a higher level of abstraction, making it easier to express complex data transformations and optimizations.
Notebooks and data pipelines are essential tools in the data architecture toolkit. Notebooks provide an interactive computing environment for data exploration, analysis, and visualization, while data pipelines enable the automated and efficient movement of data between different systems and processes.
By leveraging notebooks and data pipelines, organizations can enhance collaboration, streamline the data workflow, and accelerate the data-driven decision-making process. Notebooks provide a flexible and interactive environment for data scientists, analysts, and business users to explore and analyze data. They support various programming languages and allow for the integration of code, visualizations, and narrative explanations.
Data pipelines, on the other hand, automate the movement and transformation of data between different systems and processes. They enable organizations to establish reliable and scalable data flows, ensuring that data is delivered to the right place at the right time. Data pipelines can be designed to handle complex data transformations, data quality checks, and error handling, providing organizations with a robust and efficient data processing infrastructure.
The choice between centralized and decentralized data architecture depends on the organization's structure, culture, and data governance requirements. In a centralized architecture, data is stored and managed in a single location, ensuring consistency, control, and security. Centralized data architectures are often used in large organizations with strict data governance policies and regulatory requirements.
In a decentralized architecture, data is distributed across multiple locations, enabling greater autonomy and agility. Decentralized data architectures are commonly used in organizations with a distributed workforce, where data needs to be accessible and available at different locations. This approach allows for local decision-making and reduces the dependency on a central data infrastructure.
Each approach has its own pros and cons, and organizations must carefully consider their specific needs and priorities before deciding on the best data architecture model. Factors such as data governance, data security, scalability, and performance should be taken into account to ensure that the chosen data architecture aligns with the organization's goals and requirements.
Tools and Frameworks for Effective Data Modeling
Data modeling is a critical aspect of data architecture, facilitating the design, organization, and representation of data. Numerous tools and frameworks are available to aid in the data modeling process, ensuring accuracy, efficiency, and maintainability.
One such powerful data modeling framework is ADAPT™. ADAPT™ offers a comprehensive set of principles, methodologies, and best practices for designing and implementing data models. With its emphasis on agility, flexibility, and scalability, ADAPT™ empowers organizations to adapt quickly to evolving business requirements and data landscapes.
The Power of Data Modeling Frameworks
ADAPT™: A Cutting-Edge Data Modeling Framework
ADAPT™, short for Agile Data Architecture and Platform Transformation, is a cutting-edge data modeling framework that revolutionizes the way organizations design, implement, and manage their data architectures. This framework combines industry best practices with agile methodologies to deliver flexible, scalable, and future-proof data models.
With its focus on iterative development, collaborative design, and continuous improvement, ADAPT™ enables organizations to maximize the value of their data assets, unleash innovation, and drive digital transformation.
Where to go from here?
As data continues to play a pivotal role in today's business landscape, understanding data architecture patterns and data modeling is crucial for organizations seeking to leverage their data for competitive advantage. By demystifying these concepts and exploring specialized patterns, tools, and frameworks, organizations can unlock the full potential of their data and drive data-driven decision-making in this data-rich era.
As you navigate the complexities of data architecture patterns and data modeling, remember that the right partner can make all the difference. If you’d like to learn about our services please book a free consult here.