



High internet adoption and penetration have made it necessary for backend applications to be built for scale. Scaling the infrastructure up/down dynamically based on traffic ensures that tech acts as an enabler for the business rather than a barrier. Scaling down in times of low load makes sure that we aren’t wasting dollars in idle cycles. Growth should not be limited by tech.
Most complex applications will require you to write a batch / CRON job at some point in time.
When working with containerized applications and batch jobs you need to take care of the following:
- A job should be executed by only one container. If you have a batch job that is scheduled to run at 12 am every day, only one of the deployed containers should run it. Else it could lead to duplication, and/or unintended consequences. For example, a payments company has a batch job to send out payment reminders to customers whose bill is due. If each container runs the job, the user will be spammed with messages.
- The job status and queue shouldn’t be tied to containers. By design, the orchestrater will spawn or kill containers based on the current load. Decoupling job queuing and status from the container allows the batch jobs to be agnostic of the container that will execute it.
To fulfill the above requirements, we will hold the job queue and statuses of the jobs in Redis. The container will get the queue from Redis and will query it to get the status of the job. It will not execute the job if it is already being processed.
This tutorial assumes that you have a good understanding of
In this 3-part series, you will
- Create an endpoint that schedules a job (Part 1)
- Setup batch jobs to be executed at midnight (Part 2)
- Setup GraphQL subscriptions with Redis support (Part 3)
Starter Project
Please clone the following repository: https://github.com/wednesday-solutions/node-express-batch-jobs-starter. It contains a fully functional GraphQL Node express server.
Note: If you’re not familiar with GraphQL please take a few minutes to read the spec “here”.
Setup Redis locally
In this step, we will install and set up Redis locally and make sure that our application can connect to it.
We will be creating queues based on Redis using Bull (https://optimalbits.github.io/bull/) to:
- process scheduled jobs
- process a midnight CRON
- publish an automated notification every minute
Step 1
Install Redis locally. If you’re using a mac you can use home brew to install it
Start Redis using the command below
To install and set up Redis for Windows/Linux systems please take a look at the relevant links
- https://flaviocopes.com/redis-installation/
- https://dev.to/divshekhar/how-to-install-redis-on-windows-10-3e99
Step 2
Install bull and string-replace-loader
Add this rule to the webpack.server.config.js. Without this bull is not able to find the required .lua files.
Step 3
Add the following values in the .env. a local file
Step 4
Create the server/utils/queue.js file
Add the code below to it
- Create a constant for queue names.
- Associate the processors with the queues.
- Initialize all the queues in the initQueues method. Iterate over all the keys in queue processors.
- getQueue will create a queue with queueName if it's not already present and return it.
- queues[queueName].process(QUEUE_PROCESSORS[queueName]); will attach the functions in the QUEUE_PROCESSORS to process jobs from the appropriate queue.
Step 5
To initialize your queues
- import initQueues in the server/index.js file
- invoke initQueues like so
- setup the database and run the app using ./setup-local.sh
- If the db is already setup and you just need to run the application use yarn start: local

You should see the above logs in your console.
Commit your code using the following git commands
Write mutation for job scheduling
In this step, we will expose a mutation called scheduleJob.
Step 1
Create a new file for the job scheduler
Step 2
Copy the snippet below in the newly created file.
This mutation will accept two input parameters:
- scheduleIn represents the time in milliseconds that the job is scheduled to execute in from now.
- message represents the message to be logged when the job is executed. We will use the value of scheduleIn to delay the execution of the job added to the queue.
If the job is scheduled successfully the mutation will return { success: true } else it will return { success: false }
Step 3
Now we need to expose the mutation.
We can do this by adding the following code to the gql/mutations.js file.
Now start the application using yarn start:local . Go to http://localhost:9000/graphql in the browser. Click on Docs on the top right. Search for ScheduleJob
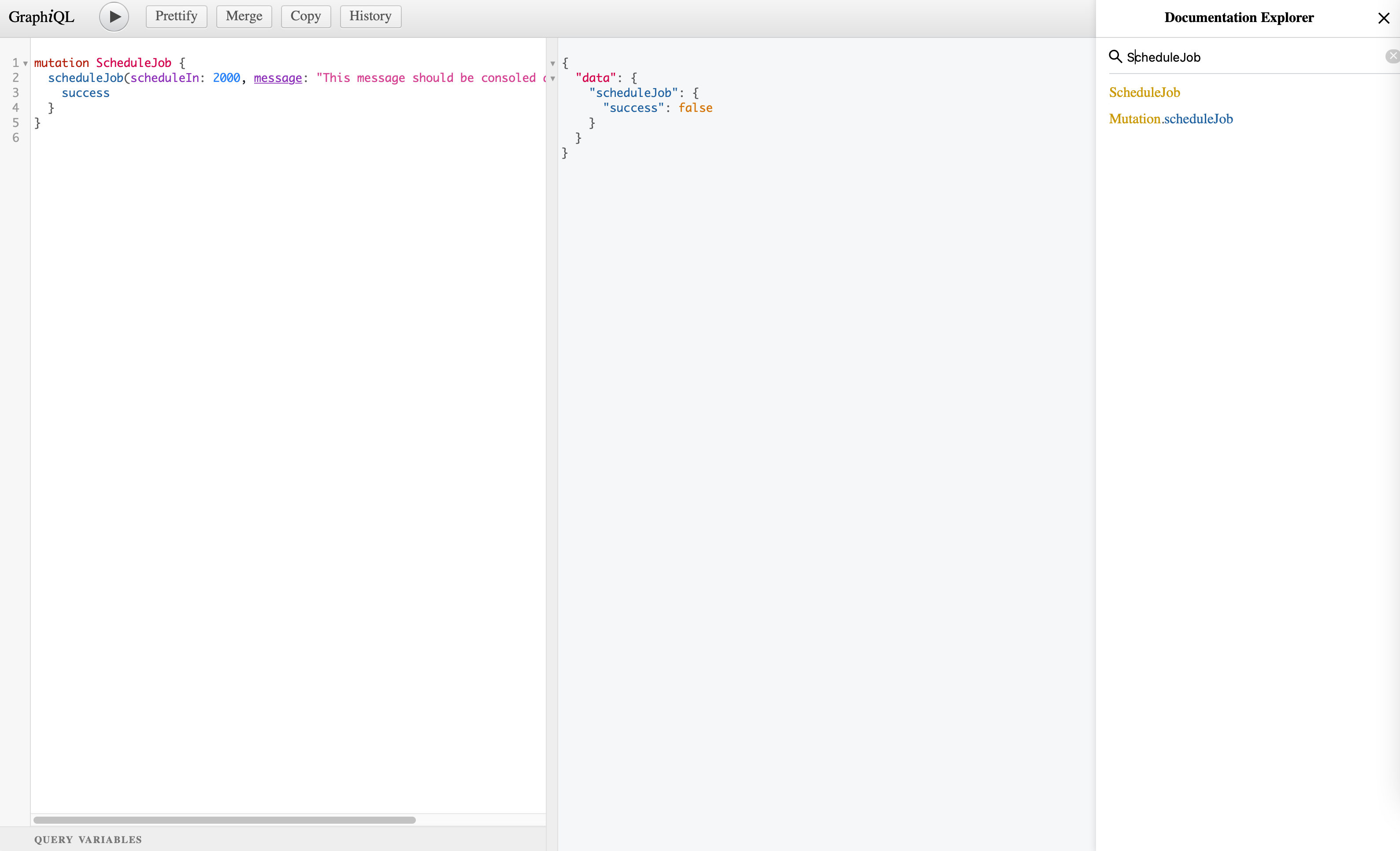
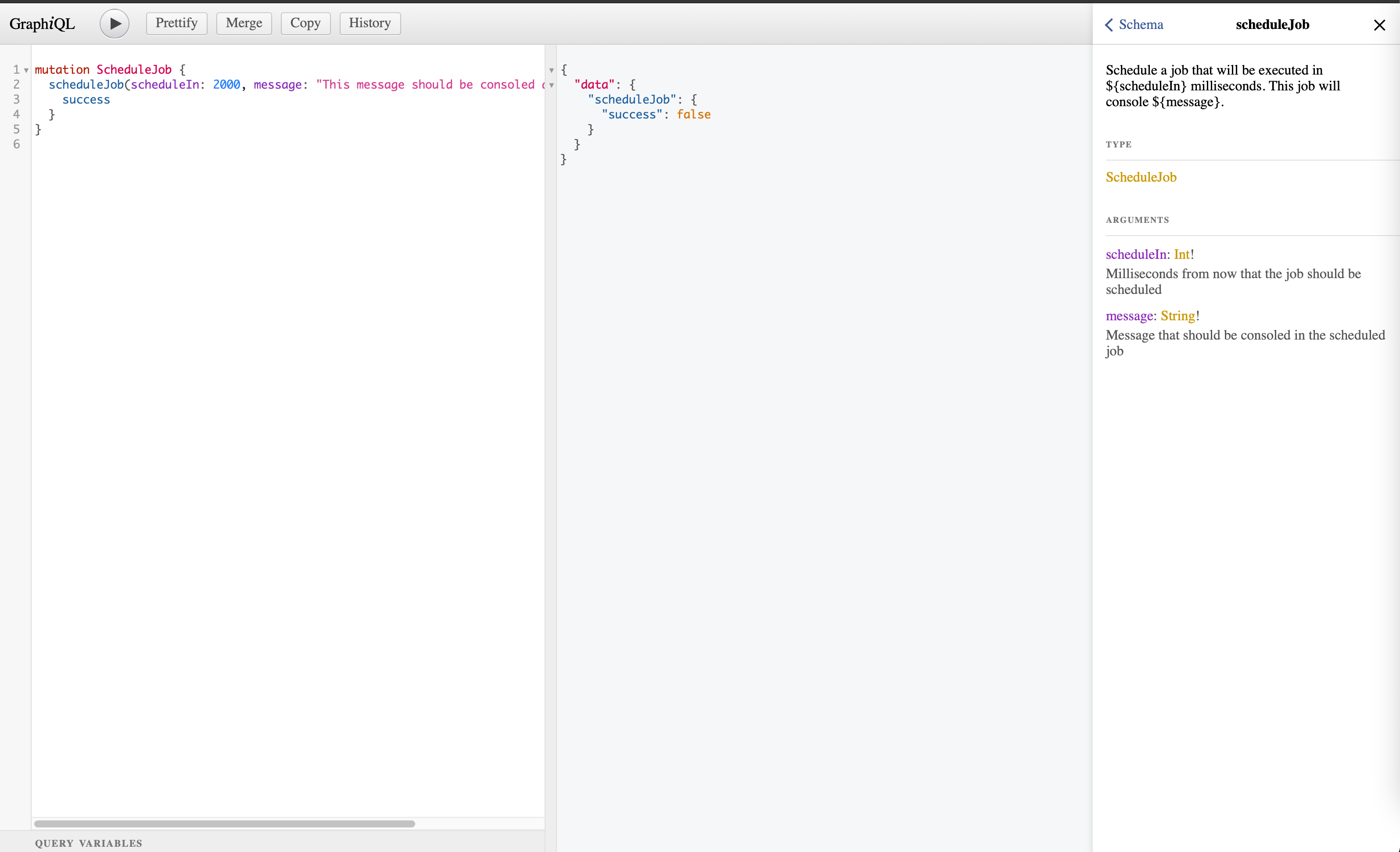
Step 4
Add the following snippet in the left pane.
Hit Play on the top left. You can also hit CMD + Enter to execute the request.
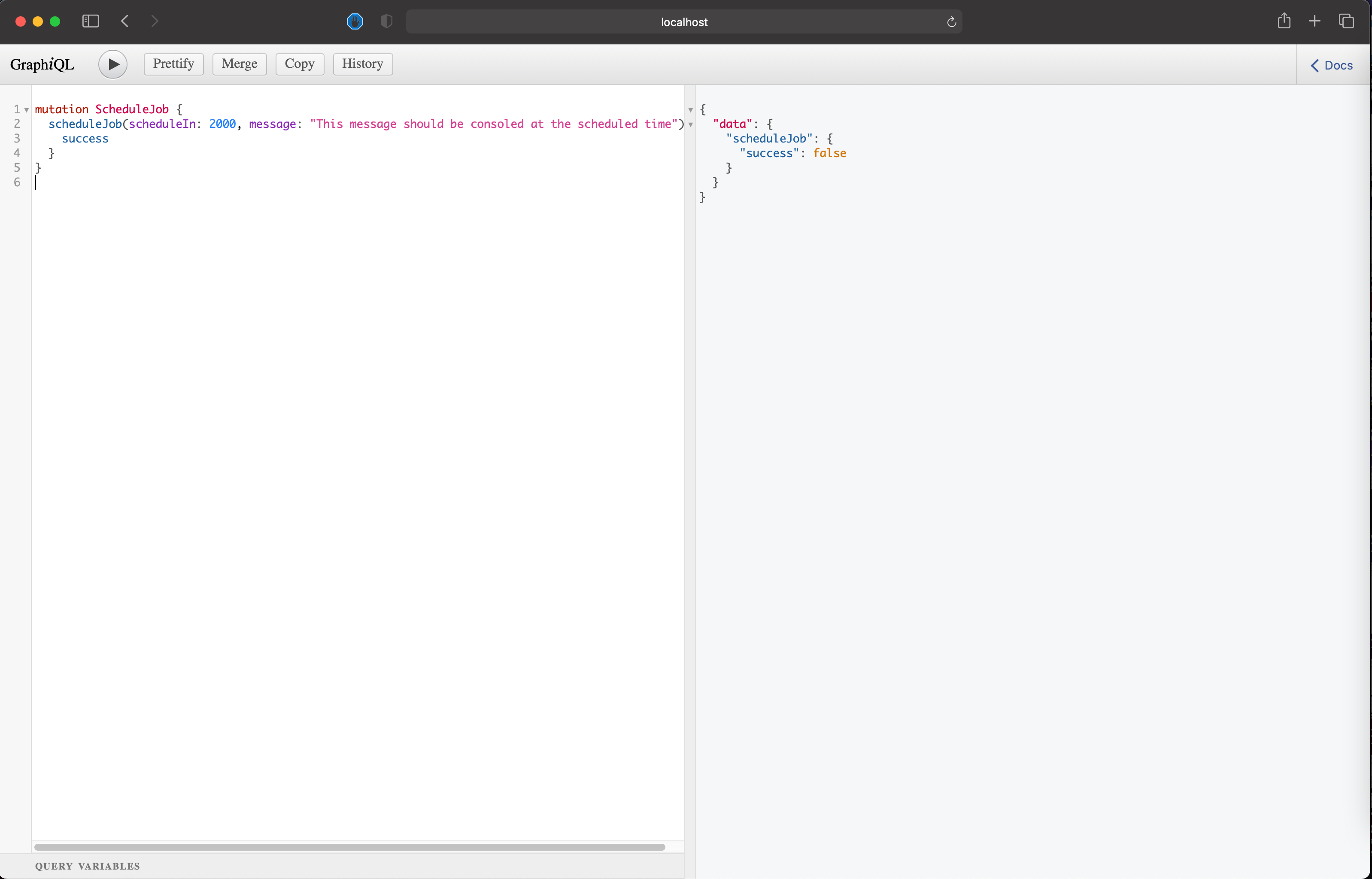
The API will respond with { success: false } since we haven't added the logic for scheduling the job. We'll get to that in a bit
Step 5
Now we will add the logic to schedule the job when the mutation is invoked.
Paste the snippet below in the resolve function.
- We get the queue by its name
- we return { success: true } if there are no errors while scheduling. Else we return { success: false }

Yay! You’ve created a mutation that schedules jobs to be executed after a set amount of time. Now test out your newly created scheduler by changing the value of scheduleIn and message.
Commit your code using the following git commands
Craving more after this read? LeadReads is where top C Execs turn for more exclusive insights and stories about digital products. Don’t be left out!
Join here.
Where to go from here
You now can schedule jobs so that they are executed in a specific amount of time!
I hope you enjoyed reading this article as much as I enjoyed writing it. If this piqued your interest stay tuned for the next article in the series where I will take you through how to schedule a CRON job that executes at midnight every day in a multi-container environment.
If you have any questions or comments, please join the forum discussion on twitter.
