

Every founder I meet has the same problem: they need to prove their idea works before money runs out, but they don't know which features actually matter. They've got a list of fifty things they want to build, customer feedback that contradicts itself, and a team (or no team) asking what to prioritize. The pressure is real. Series A capital is meant to get to product-market fit, not to build a perfect product.
This is where startup MVP development becomes critical. But here's what most founders get wrong: they think an MVP is just a stripped-down version of their full vision. They cut features, ship fast, and hope users show up. What they miss is that the architecture underneath matters as much as the features on top. A poorly architected MVP becomes a liability. It slows down iteration. It creates technical debt that compounds with every sprint. It turns a startup that should be moving fast into one that's fighting its own codebase.
Startup MVP development workflow visualization showing iterative feature prioritization and scalable growth strategy
The startups that win are the ones that build MVPs with scalable architecture from day one. Not over-engineered. Not premature optimization. But thoughtful enough that when you need to add features, change direction, or scale up, you're not rewriting everything from scratch. This is the difference between an MVP that teaches you something and an MVP that wastes three months of runway.
I've watched this across fifty-plus engagements. The pattern is consistent: founders who think about architecture early move faster, iterate more, and find product-market fit with less wasted capital. Those who don't end up rebuilding six months in, which is capital they didn't have to spend.
Why traditional MVP approaches fail startups
Dashtechinc research shows that 90% of startups launching their first MVP underestimate the technical foundation required for iteration. Most founders focus on feature count, not architecture resilience. They ship a product that works for the first thousand users, then hit a wall when they need to add features or scale.
The core issue is that startup MVP development is treated as a binary: either you're building a throwaway prototype, or you're building a production system. Both approaches fail. A throwaway prototype teaches you nothing because it's so limited that users can't actually interact with your core value. A production system wastes months on infrastructure that you don't need yet.
What actually works is a third path: build an MVP with scalable architecture that prioritizes learning over perfection. This means choosing technologies that scale without redesign, designing your database schema to handle the next phase of growth, and structuring code so that adding features doesn't break existing ones.
2026 MVP development trends emphasize modular architecture as a key differentiator between MVPs that survive iteration and those that collapse under their own weight. Startups that build modular systems from the start can swap components, add new features, and pivot without rewriting their core.
The cost of getting this wrong is high. I worked with a Series A fintech company that shipped their MVP with a monolithic codebase, no API separation, and a database schema that couldn't handle multi-tenant data. Six months later, they needed to add features for their first enterprise customer. Instead of two sprints, it took eight because the entire codebase was coupled. That's capital they could have spent on sales and marketing.
The architecture decisions that matter for startup MVP development
When I talk to founders about startup MVP development, they often ask: should we use microservices? Should we containerize? Should we build for scale? The answer is always the same: it depends on what you're learning, not on what sounds technically impressive.
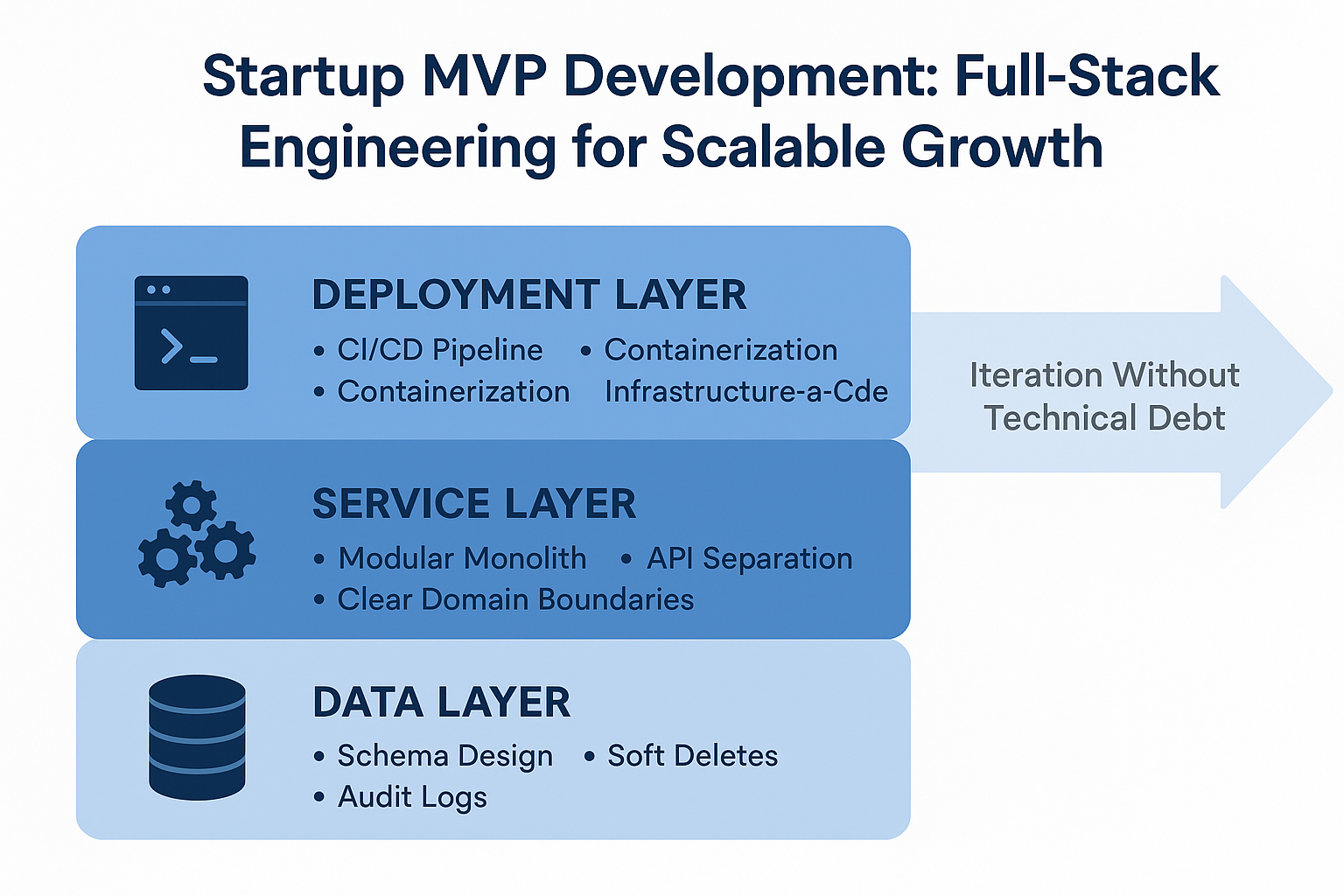
The architecture decisions that actually matter for an MVP fall into three categories: data architecture, service architecture, and deployment architecture.
Data architecture is where most founders make their first mistake. They pick a database technology (usually PostgreSQL or MongoDB) and assume it'll work fine for the MVP. The problem isn't the database choice. It's the schema design. If you build your schema assuming a single tenant, single geography, and a fixed set of user types, you'll hit a wall when you need to support multiple organizations, regional compliance, or different user roles. A scalable MVP schema is designed to evolve. It uses soft deletes instead of hard deletes. It tracks audit logs. It separates business logic from data structure. It's not over-normalized, but it's not a mess either.
Service architecture determines how easy it is to add features without breaking existing ones. The common mistake is building a monolith where every feature lives in the same codebase, database, and deployment. This works until you need to add a feature that requires different scaling characteristics, a different tech stack, or a different team. A scalable MVP service architecture starts with clear domain boundaries. You're not building microservices. You're building a modular monolith or a lightweight API layer that separates your core business logic from your presentation layer. This means when you need to add a new feature, it doesn't require changes to five other parts of the system.
Deployment architecture is about reducing friction between code and production. If your MVP requires manual deployment steps, environment configuration, or downtime to release, you're slowing down iteration. A scalable MVP uses containerization (Docker), infrastructure-as-code (Terraform or CloudFormation), and CI/CD pipelines. Not because you need to scale to a million users. But because you need to ship features without fear, roll back quickly if something breaks, and measure the impact of changes in production.
Vention research indicates that startups with CI/CD pipelines in place from MVP launch iterate 3x faster than those without. The difference isn't in the technology. It's in confidence. When you can deploy in five minutes and roll back in two, you're willing to ship more often, test more hypotheses, and learn faster.
Validation before you build: the framework that saves runway
Here's the uncomfortable truth about startup MVP development: most founders start building before they've validated what to build. They have a hypothesis about what users want, but they've never tested it. They ship code, get feedback, and then spend two sprints rewriting because they built the wrong thing.
The framework that changes this is validate before you build. It sounds simple. It's not. It requires discipline to resist the urge to code.
Validation happens in stages. First, you run customer conversations to decode what users actually mean when they say something. A user says "I want better reporting." What they mean is "I'm spending two hours a week manually pulling data from your system into a spreadsheet." The solution isn't a reporting dashboard. It's an API export. But you only know this if you ask the right questions.
Second, you test your hypothesis with a small prototype or landing page. Not code. A Figma prototype, a video, or a landing page that describes the feature and measures interest. If you can't get users excited about a Figma prototype, they won't be excited about the built version either. This saves weeks of development.
Third, you measure the impact. When you ship a feature, you don't just count users who use it. You measure whether it moves the needle on your core metric. Did it increase activation? Reduce churn? Increase revenue? If the answer is no, you stop building that feature, no matter how much time you've invested. This is capital discipline.
MicroVentures found that startups that validate before building reduce their time-to-PMF by 40% on average. The difference isn't that they're smarter. It's that they're not building the wrong thing.
This validation framework changes how you think about startup MVP development. You're not trying to build a perfect product. You're trying to learn the fastest way possible what users actually want. Every sprint should move you closer to that answer or eliminate a hypothesis. If a sprint doesn't do either, you're wasting runway.
AI-native startup MVP development: where iteration happens faster
Startup MVP development in 2026 looks different than it did two years ago. The difference is AI. Not AI as a feature you add to your product (though that might be part of it). But AI as a tool that makes the engineering team faster.
AI-native development means using large language models to accelerate common tasks: code generation, test writing, documentation, and debugging. A full-stack engineer using AI can write twice as much code in the same time. They spend less time on boilerplate and more time on logic that matters.
But there's a catch. AI is a multiplier. If you give AI to a mediocre engineer, they write mediocre code faster. If you give AI to a strong engineer, they write good code much faster. For startup MVP development, this means you need engineers who understand architecture and can evaluate what AI generates. They need to know when to accept the AI suggestion and when to override it.
The second way AI changes startup MVP development is through testing and validation. Instead of writing test cases manually, you can generate them. Instead of manually testing different user flows, you can use AI to generate test scenarios. This means you catch bugs earlier and validate features faster.
The third way is through monitoring and observability. AI can analyze logs and metrics to identify anomalies. It can alert you when something is wrong before users notice. For an MVP with limited infrastructure expertise, this is valuable. You get production visibility without hiring a DevOps engineer.
The key is not to use AI as a replacement for good engineering. Use it as an accelerant for good engineering. The startups that win are the ones that have strong engineers using AI tools effectively, not ones that try to replace engineers with AI.
Real-world example: From confused roadmap to validated MVP in 16 weeks
A Series A logistics startup came to us with a problem: they had raised capital but had no clear direction. Their founder had fifty feature ideas, contradictory customer feedback, and a team of two engineers asking what to build next. They'd been working for three months and had shipped nothing meaningful. Runway was burning.
The startup's problem wasn't technical. It was strategic. They didn't know what to build first because they hadn't validated which features would move the needle. They were trying to be everything to everyone.
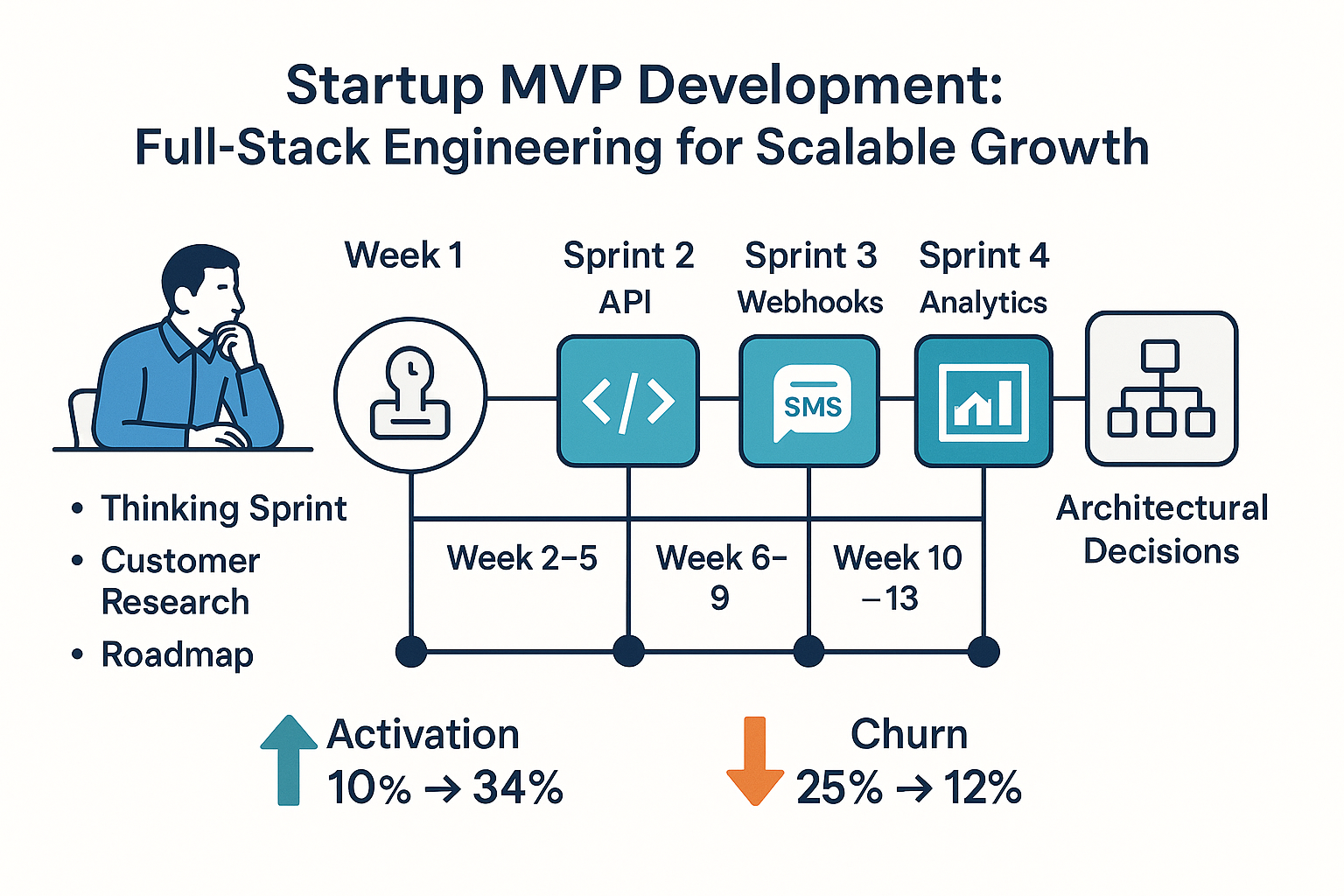
Here's what we did. Week one was a thinking sprint. We ran customer conversations with their top 20 users. We asked them what problem they were actually trying to solve. We watched them use the product. We decoded the gap between what they said they wanted and what they actually needed.
The founder thought users wanted advanced reporting. What they actually wanted was a way to quickly check the status of a shipment without logging in. The founder thought users wanted multiple warehouse support. What they actually needed was better data sync between their existing warehouse system and the logistics platform.
Based on that validation, we built a roadmap. Four sprints. Four outcomes. Sprint one: build a public status page API so users could embed shipment status on their own sites. Sprint two: build a webhook system so data could sync automatically. Sprint three: add SMS notifications so users could get updates without logging in. Sprint four: build an analytics dashboard focused on the one metric that mattered: on-time delivery rate.
Each sprint was a vibe sprint. Not agile stories. Business outcomes. Measure success by whether the feature moved the needle, not by how many story points we completed.
By week sixteen, the startup had shipped four features that users actually wanted. Activation went from 10% to 34%. Churn dropped from 25% to 12%. They had real data to show investors. They had a product that was solving a specific problem for a specific user. They had product-market fit signals.
The architecture underneath was scalable. We built with modular code, clear API boundaries, and a CI/CD pipeline. When they needed to add features, they could do it without rewriting. The database schema was designed to handle the next phase. The code was structured so that adding a new feature didn't require changes to five other systems.
The difference wasn't the technology. It was the approach. Validate what to build before you build it. Build with architecture that allows iteration. Use full-stack engineers who can move fast. Measure success by business outcomes, not by code shipped.
Looking to accelerate your engineering delivery? Wednesday Solution's Launch Service helps engineering teams ship faster and more reliably.
Choosing the right tech stack for scalable MVP development
One question I get constantly: what tech stack should we use for our MVP? The answer is almost never the flashy new framework. It's the one that lets your team move fastest and scales without major rewrites.
For backend, I usually recommend Node.js, Python, or Go. All three have mature ecosystems, strong libraries, and the ability to scale. Pick based on what your team knows best. A team that knows Python will move faster with Python than with Go, even if Go is technically superior.
For frontend, React or Vue. Both are mature. Both have strong ecosystems. Both can be deployed anywhere. The difference is minimal. Pick based on team preference.
For database, PostgreSQL or MongoDB. PostgreSQL if your data is structured and relational. MongoDB if you need flexibility in schema. Both scale. Both have mature tooling. The common mistake is picking based on hype instead of based on your data model.
For deployment, Docker and Kubernetes if you have DevOps expertise. Docker and managed services (AWS ECS, Google Cloud Run) if you don't. The managed services are more expensive per unit but cheaper in total cost because you're not hiring a DevOps engineer.
The principle is this: choose technologies that are boring, mature, and widely used. The startup graveyard is full of companies that bet on the new hotness and spent six months fighting tooling instead of building features. Choose technologies where the hard problems have already been solved and the community is large enough that you can find answers to questions.
FAQs
Which cloud platform is best for MVP development?
AWS offers scalable infrastructure for MVPs, but Firebase simplifies backend setup. Choose based on your team's expertise and growth needs.
How can Firebase speed up MVP development?
Firebase provides ready-to-use auth, databases, and hosting, letting founders focus on core features instead of backend setup.
What are some successful MVP examples?
Dropbox's video demo and Airbnb's simple site proved demand before full builds. Both prioritized learning over perfection.
Last updated: March 16, 2026
